I need some web scraping guidance. I want to scrape the GICS industry code for different stocks from the URL https://digital.fidelity.com/prgw/digital/research/quote/dashboard/summary?symbol=IBM
HttpClient returns the DOM source of that URL okay, but it is exclusively compose of navigational menu stuff. The actual content for scraping is rendered via JavaScript scripts. My questions are
1) How do I determine which script renders the content I want to scrape, the GICS industry code? I assume that's done with the DOM Inspector on Firefox, but I don't see how to trace it.
2) What's the easiest way to render the appropriate script into a scrapable string? Is there a recommended scraping tool I should be using for this or are low-level .NET calls good enough?
The DOM inspector (on Firefox) can easily locate the string (GICS industry code) for scraping in the screenshot below. I just don't know how to reach it from the output HttpClient returns for this URL.
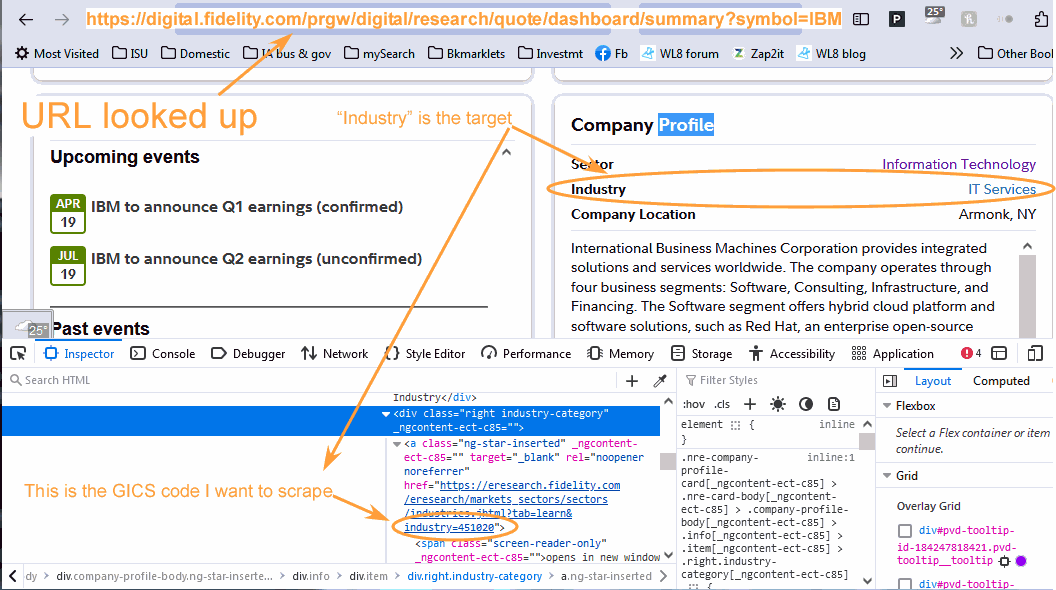
HttpClient returns the DOM source of that URL okay, but it is exclusively compose of navigational menu stuff. The actual content for scraping is rendered via JavaScript scripts. My questions are
1) How do I determine which script renders the content I want to scrape, the GICS industry code? I assume that's done with the DOM Inspector on Firefox, but I don't see how to trace it.
2) What's the easiest way to render the appropriate script into a scrapable string? Is there a recommended scraping tool I should be using for this or are low-level .NET calls good enough?
The DOM inspector (on Firefox) can easily locate the string (GICS industry code) for scraping in the screenshot below. I just don't know how to reach it from the output HttpClient returns for this URL.
Rename
You can use PuppeteerSharp library: https://learn.microsoft.com/en-us/microsoft-edge/puppeteer/
It references a number of DLLs, so I recommend you build yourself a little Windows Forms or WPF app and use the following event handler. The following code is just a button click handler (in WPF). Note that the Puppeteer browser must set Headless = false (see the code) or Fidelity will gripe with unauthorized access. In the following code, txtOutput is just a TextBlock control. Of course, you'll adjust for your own needs. (The Windows Presentation Foundation window here is awful as I didn't put a lot into it!) And, in the call to page.GoToAsync(...) you want to use option WaitUntilNavigation.Networkidle2 so that the JavaScript runs and you end up with the completed page.
Also see: https://www.kiltandcode.com/puppeteer-sharp-crawl-the-web-using-csharp-and-headless-chrome/
Code below is written for C# 10.0...
It references a number of DLLs, so I recommend you build yourself a little Windows Forms or WPF app and use the following event handler. The following code is just a button click handler (in WPF). Note that the Puppeteer browser must set Headless = false (see the code) or Fidelity will gripe with unauthorized access. In the following code, txtOutput is just a TextBlock control. Of course, you'll adjust for your own needs. (The Windows Presentation Foundation window here is awful as I didn't put a lot into it!) And, in the call to page.GoToAsync(...) you want to use option WaitUntilNavigation.Networkidle2 so that the JavaScript runs and you end up with the completed page.
Also see: https://www.kiltandcode.com/puppeteer-sharp-crawl-the-web-using-csharp-and-headless-chrome/
Code below is written for C# 10.0...
CODE:
using System; using System.Windows; using PuppeteerSharp; namespace ScrapeWebPage; public partial class MainWindow : Window { public MainWindow() { InitializeComponent(); } private async void RunButton_OnClick(object sender, RoutedEventArgs e) { await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultChromiumRevision); var browser = await Puppeteer.LaunchAsync(new LaunchOptions { Headless = false // set false or Fidelity will not let you get to the content }); var page = await browser.NewPageAsync(); page.DefaultTimeout = 5000; await page.GoToAsync("https://" + $"digital.fidelity.com/prgw/digital/research/quote/dashboard/summary?symbol=AAPL", WaitUntilNavigation.Networkidle2); // WaitUntilNavigation.Networkidle2 for JS completion var content = await page.GetContentAsync(); await browser.CloseAsync(); // of course, adjust to your needs... var index = !string.IsNullOrEmpty(content) ? content.IndexOf("industry=", StringComparison.Ordinal) : -1; if (index >= 0) { var ind = content.Substring(index, content.IndexOf('"', index) - index); txtOutput.Text = ind; } else { txtOutput.Text = "Industry not found"; } } }
CODE:
<Window x:Class="ScrapeWebPage.MainWindow" xmlns="<a href="http://schemas.microsoft.com/winfx/2006/xaml/presentation" target="_blank">http://schemas.microsoft.com/winfx/2006/xaml/presentation</a>" xmlns:x="<a href="http://schemas.microsoft.com/winfx/2006/xaml" target="_blank">http://schemas.microsoft.com/winfx/2006/xaml</a>" xmlns:d="<a href="http://schemas.microsoft.com/expression/blend/2008" target="_blank">http://schemas.microsoft.com/expression/blend/2008</a>" xmlns:mc="<a href="http://schemas.openxmlformats.org/markup-compatibility/2006" target="_blank">http://schemas.openxmlformats.org/markup-compatibility/2006</a>" xmlns:local="clr-namespace:ScrapeWebPage" mc:Ignorable="d" Title="MainWindow" Height="450" Width="800"> <StackPanel x:Name="LayoutRoot" Margin="10"> <Button x:Name="runButton" Content="Run" Click="RunButton_OnClick" Width="150" Height="20"></Button> <TextBlock x:Name="txtOutput" Margin="5,8,8,0" Height="300" TextWrapping="WrapWithOverflow">hellos</TextBlock> </StackPanel> </Window>
I don't want to call a separate application like puppeteer. I'm looking for some simple library calls I can build into an existing C# class library I use with WL now. I do not want to run a separate application.
I have though about trying to render the entire web page--including all JavaScript--then scrape that as a string. Seems brute force though.
This should be simple to do. I just want to scrape a web page with minimal fuss. Did I mention my knowledge of WPF is very poor. I'm from the embedded systems world, not the Windows world.
I have though about trying to render the entire web page--including all JavaScript--then scrape that as a string. Seems brute force though.
This should be simple to do. I just want to scrape a web page with minimal fuss. Did I mention my knowledge of WPF is very poor. I'm from the embedded systems world, not the Windows world.
Well, I tried.
One would need Puppeteer or solutions of the similar scale to step over some serious walls like CloudFlare or ReCaptcha. And the battle of the armor and missile goes on. IMHO, it's overkill to apply this kind of tool on Fidelity's web pages.
Try asking ChatGPT. I've heard of it generating full code blocks that people have used for just such a purpose (scraping). Haven't tried it myself.
Note that the more specific the query the better is CGPT's answer.
Good luck!
Note that the more specific the query the better is CGPT's answer.
Good luck!
I'm still trying to understand the steps required for solving this problem. Rather than the solution given in Reply# 1, which requires building an independent Windows app, I would like to see how Reply# 1 can be implemented in Initialize(...) within WL8 without the WPF part. From that, I can figure out how to move the implementation into a C# library call.
In my research, what's needed to scrape a webpage containing JavaScript is a "headless browser," which will (1) download the webpage, (2) execute the JavaScript, and (3) return a string that can be parsed. That appears to be what puppeteer is all about. Puppeteer may be a good headless browser choice because everyone already has Chromium (i.e. Microsoft Edge) installed, which implements puppeteer. But I'm still researching/reading about how this process works.
I haven't used ChatGPT before, and I'm not even sure how to formulate the question well enough to get a precise answer.
In my research, what's needed to scrape a webpage containing JavaScript is a "headless browser," which will (1) download the webpage, (2) execute the JavaScript, and (3) return a string that can be parsed. That appears to be what puppeteer is all about. Puppeteer may be a good headless browser choice because everyone already has Chromium (i.e. Microsoft Edge) installed, which implements puppeteer. But I'm still researching/reading about how this process works.
I haven't used ChatGPT before, and I'm not even sure how to formulate the question well enough to get a precise answer.
Go on YouTube, search for something like... "chatGPT + scraping" or similar.
@superticker - The code I provided is for obtaining the industry codes for storage so that your code can later efficiently obtain the codes from storage for use in your strategies. Yes, it would be awful to call a WPF app from a strategy to obtain the codes each time your strategies needed to use them.
I'm going to assume you need to have efficient access, by strategies, for the industry code of any symbol. A reasonably efficient way to do that could be to have the symbol to industry code mappings in a csv file. The csv file can be read into a Dictionary instance. In turn your code can use the Dictionary accordingly. To demonstrate a specific use case of this solution, albeit for my use case I use a HashSet<string>, my library reads a file containing symbols that can NOT be shorted by my broker. I have a method, that when asked if a symbol can be shorted, will check if the symbol set has already been loaded from the file. And, if not, the method will load the file and pop the symbols into the HashSet, and finally return true or false about shorting the symbol. If the file has already been loaded, it doesn't reload it. That would be hideous. The method about shorting can be called from anywhere in my code (strategy or library). There is no noticeable degredation of performance when running optimizations.
So here are a couple of solutions...
Using Puppeteer, there are only the few lines of code for obtaining the information you need. Given that you already have a C# class library, you could just fetch Puppeteer using Nuget into your library. Then write a method containing the subset of code that I posted. Write a dummy strategy that from its Initialize method, calls the method in a loop with the symbols to obtain their respective industry codes and store those in the csv file. That way you don't have to deal with WPF or Windows forms. However, you probably would have to have all of the DLLs that Puppeteer references copied into your WL8 folder (a pain). I didn't actually try this, so there may be some obstacles along the way. Also, be aware that if you hit Fidelity's servers too frequently, you may end up getting throttled. That in itself is a pain to deal with.
Another option would be to obtain the industry codes from some other medium than Fidelity. Perhaps a list or file of the information is available via the net. If so, you could then easily build the csv file.
If there are alot of mappings that you need, such that the csv file causes performance issues, then you could have a static Dictionary in your library, which would be super fast. However, maintenance pitfalls are obvious.
I'm going to assume you need to have efficient access, by strategies, for the industry code of any symbol. A reasonably efficient way to do that could be to have the symbol to industry code mappings in a csv file. The csv file can be read into a Dictionary instance. In turn your code can use the Dictionary accordingly. To demonstrate a specific use case of this solution, albeit for my use case I use a HashSet<string>, my library reads a file containing symbols that can NOT be shorted by my broker. I have a method, that when asked if a symbol can be shorted, will check if the symbol set has already been loaded from the file. And, if not, the method will load the file and pop the symbols into the HashSet, and finally return true or false about shorting the symbol. If the file has already been loaded, it doesn't reload it. That would be hideous. The method about shorting can be called from anywhere in my code (strategy or library). There is no noticeable degredation of performance when running optimizations.
So here are a couple of solutions...
Using Puppeteer, there are only the few lines of code for obtaining the information you need. Given that you already have a C# class library, you could just fetch Puppeteer using Nuget into your library. Then write a method containing the subset of code that I posted. Write a dummy strategy that from its Initialize method, calls the method in a loop with the symbols to obtain their respective industry codes and store those in the csv file. That way you don't have to deal with WPF or Windows forms. However, you probably would have to have all of the DLLs that Puppeteer references copied into your WL8 folder (a pain). I didn't actually try this, so there may be some obstacles along the way. Also, be aware that if you hit Fidelity's servers too frequently, you may end up getting throttled. That in itself is a pain to deal with.
Another option would be to obtain the industry codes from some other medium than Fidelity. Perhaps a list or file of the information is available via the net. If so, you could then easily build the csv file.
If there are alot of mappings that you need, such that the csv file causes performance issues, then you could have a static Dictionary in your library, which would be super fast. However, maintenance pitfalls are obvious.
Is there really a need to scrape GICS?
The Norgate data provider can already return GICS codes. If the feature hasn't already been documented, look for explanation in Post #13 of a thread on Norgate.
The Norgate data provider can already return GICS codes. If the feature hasn't already been documented, look for explanation in Post #13 of a thread on Norgate.
@superticker - if you didn't want to pursue the Norgate solution, then here is a Windows Console scraper app I put together to fetch and save the symbols and their respective GICS codes to a csv file (see my suggestion in post 8 above). This is a .NET 6 console application written in C# 10.0. Of course, you'll need to Nuget PuppeteerSharp into the solution...
CODE:
using PuppeteerSharp; // put the symbols you want to scrape here... var symbols = new List<string> { "AAPL", "IBM", "MSFT", "AMD", "INTC", "RBLX", "U", "SNAP", "PTON" }; // change file path to suit your environment... const string gicsFile = @"C:\Users\Paul\Documents\GICS.csv"; var symbolToGicsMap = new Dictionary<string, string>(); if (File.Exists(gicsFile)) { var content = File.ReadAllLines(gicsFile); foreach (var line in content) { if (!string.IsNullOrWhiteSpace(line)) { var parts = line.Split(','); symbolToGicsMap[parts[0]] = parts[1]; } } } await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultChromiumRevision); var browser = await Puppeteer.LaunchAsync(new LaunchOptions { Headless = false // set false or Fidelity will not let you get to the content }); var page = await browser.NewPageAsync(); page.DefaultTimeout = 10000; for (var i = 0; i < symbols.Count; i++) { var symbol = symbols[i]; if (symbolToGicsMap.ContainsKey(symbol)) { continue; } try { await page.GoToAsync( "https://" + $"digital.fidelity.com/prgw/digital/research/quote/dashboard/summary?symbol={symbol}", WaitUntilNavigation.Networkidle2); var content = await page.GetContentAsync(); var index = !string.IsNullOrEmpty(content) ? content.IndexOf("industry=", StringComparison.Ordinal) : -1; if (index >= 0) { var ind = content.Substring(index + "industry=".Length, 6); File.AppendAllText(gicsFile, $"{symbol},{ind}{Environment.NewLine}"); } else { Console.WriteLine($"Industry not found for symbol {symbol}"); } // hopefully this prevents throttling // note: don't sleep after the last fetch - waste of time if (i < symbols.Count - 1) { Thread.Sleep(2000); } } catch (Exception e) { Console.WriteLine(e); } } await browser.CloseAsync();
Thank you for the Concierge level support!!
QUOTE:
The Norgate data provider can already return GICS codes.
Yes, but I'm not going to give up IQFeed, and I'm not going to pay for both IQFeed and Norgate just to get GICS codes. Now if I can get GICS codes from Norgate without paying, then keep talking. :)
QUOTE:
The csv (tab delimited in my case) file can be read into a Dictionary instance.
I'm already doing that and using StreamWriter to write that Dictionary instance (cache) to disk. My problem is Fidelity changed its website to now render with JavaScript, which I never scraped before. So I'm on new ground with scraping JavaScript-based webpages. All other aspects are already coded four years ago.
I'm looking deeper into PuppeteerSharp, which is a very capable solution. But that's part of the problem; it's major overkill for what I want to do. All I want to do is execute some javascript on a webpage. I don't need to steer the browser in special ways. Is there a simpler .NET based scraper than PuppeteerSharp?
I'm looking at Playwrite.NET https://github.com/microsoft/playwright-dotnet right now thinking it's good enough for my simple needs. Any other suggestions?
There's a review of headless browsers: https://github.com/dhamaniasad/HeadlessBrowsers But these solutions seem like an overkill to me if all I want to do is scrape a javascript-based website with a .NET-based library.
I'm trying to execute the following command-line on Windows with headless Chrome with marginal success. I'm wondering if my results are typical or if everyone gets the same thing? I'm following the directions on https://developer.chrome.com/blog/headless-chrome/
IMPORTANT: I added an extraneous "9" in the "http" part of the two above URLs; otherwise, the WL website will adulterate them. Just remove the "9", then run the command.
The first URL case works as expected, however, out.txt is truncated somewhat. Why is that? Is that unique to my system?
The second URL case creates out.txt file okay, but the file is totally empty. Is that because Fidelity's website can't be scraped with Google Chrome?
My Chrome version is: Version 109.0.5414.120 (Official Build) (64-bit)
CODE:
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --headless --disable-gpu --dump-dom h9ttps://www.chromestatus.com/ > out.txt "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --headless --disable-gpu --dump-dom h9ttps://digital.fidelity.com/prgw/digital/research/quote/dashboard/summary?symbol=IBM > out.txt
IMPORTANT: I added an extraneous "9" in the "http" part of the two above URLs; otherwise, the WL website will adulterate them. Just remove the "9", then run the command.
The first URL case works as expected, however, out.txt is truncated somewhat. Why is that? Is that unique to my system?
The second URL case creates out.txt file okay, but the file is totally empty. Is that because Fidelity's website can't be scraped with Google Chrome?
My Chrome version is: Version 109.0.5414.120 (Official Build) (64-bit)
Try including the --enable-logging option.
QUOTE:
Try including the --enable-logging option.
No change. I also tried a delay and without the "--headless" flag but that still doesn't work to populate out.txt.
So are you able to get this to work on your system? I'm assuming you can. I just want to be sure this Fidelity webpage can be scraped by Chrome in the first place; otherwise, we are wasting our time.
I added a "9" in the http part so the WL website doesn't mess with the URL below. Be sure to remove that "9" first.
CODE:
"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --headless --disable-gpu --dump-dom --enable-logging h9ttps://digital.fidelity.com/prgw/digital/research/quote/dashboard/summary?symbol=IBM > out.txt & timeout 3
I'm studying the webpage source more closely. The entire main body content is generated by javascript that's compressed. I think they made it intentionally hard to scrape. I'm over my head.
Not sure if this helps but I use the SIC and NAICS codes provided by IQFeed. They provide a file updated daily with all the instruments. Here is the code I use to download it and read it.
Download File
Read File
Download File
CODE:
private static async Task<bool> InstrumentFileUpdateAsync() { string zipFilePath = Path.Combine(Path.GetTempPath(), "IQFeedInstruments.zip"); // ReSharper disable once StringLiteralTypo const string instrumentUrl = @"<a href="http://www.dtniq.com/product/mktsymbols_v2.zip" target="_blank">http://www.dtniq.com/product/mktsymbols_v2.zip</a>"; // Check file existence and age bool fileIsThere = File.Exists(InstrumentFilePath); DateTime fileModificationDate = File.GetLastWriteTime(InstrumentFilePath).Date; TimeSpan fileAge = DateTime.Now.Date - fileModificationDate; bool fileUpdated = fileIsThere && fileAge.Days < InstrumentFileDays; // Already Updated if (fileUpdated) return false; // Update File if (File.Exists(zipFilePath)) { File.Delete(zipFilePath); } WebClient web = new(); await web.DownloadFileTaskAsync(instrumentUrl, zipFilePath).ConfigureAwait(false); if (!File.Exists(zipFilePath)) { throw new Exception($"{nameof(InstrumentFileUpdateAsync)}: download of {instrumentUrl} failed."); } // Unzip File if (File.Exists(InstrumentFilePath)) { File.Delete(InstrumentFilePath); } await Task.Run(() => ZipFile.ExtractToDirectory(zipFilePath, Config.DataPath)).ConfigureAwait(false); if (!File.Exists(InstrumentFilePath)) { throw new Exception($"{nameof(InstrumentFileUpdateAsync)}: unzip of {instrumentUrl} failed."); } Logger.Instance.Data($"{nameof(InstrumentFileUpdateAsync)} Complete."); return true; }
Read File
CODE:
private static IEnumerable<Instrument> InstrumentFile() { int lineCount = 0; using StreamReader file = new(InstrumentFilePath); string[] values; while (file.ReadLine() is { } line && (values = line.Split('\t')).Length == 8) { lineCount++; if (lineCount == 1) // ignore the header { continue; } yield return new Instrument( values[0], description: values[1], exchange: values[2], listedExchange: values[3], instrumentType: values[4], sic: int.TryParse(values[5], NumberStyles.Any, CultureInfo.InvariantCulture, out int tSic) ? tSic : -1, isFrontMonth: values[6] == "Y", naics: int.TryParse(values[7], NumberStyles.Any, CultureInfo.InvariantCulture, out int tNaics) ? tNaics : -1, ts: DateTime.MinValue); } }
QUOTE:
NAICS codes provided by IQFeed
I thought about using NAICS codes years ago, which are in the public domain and I believe managed by the US Bureau of Standards. But after reviewing them carefully, I prefer the GICS industry classifications much better.
Part of the problem is that a single company could be associated with several NAICS codes, which is confusing to me. Yes I realize large companies can be involved in several industries so having several NAICS codes for one large company can make sense. But I prefer to have just one salient GICS code per company. That simplifies things for me (even if it's not ideal).
But some users might be interested in your NAICS code solution, which is in the public domain so it's more accessible via more providers--a plus.
If topic starter is interested I can quickly build a solution that would grab the GICS code from Fidelity's page straight in a WealthScript strategy. Neither a headless browser nor Javascript parsing is required. You're welcome to contact us through our Concierge Support Service.
Your Response
Post
Edit Post
Login is required