You create a day trading profitable strategy, you backtest it, you optimize it using WFO and a long history (in order to have lots of data), you put it to paper trading and...
Oh, the horror, the horror!!!! IoI
It´s overfitted!!!!!!!
How do you avoid overfitting? Is there an indicator to identify overfitted strategies? How do you correct overfitting?
This is a question for the entire community.
Oh, the horror, the horror!!!! IoI
It´s overfitted!!!!!!!
How do you avoid overfitting? Is there an indicator to identify overfitted strategies? How do you correct overfitting?
This is a question for the entire community.
Rename
The only way I know of to avoid clear overfitting it to:
1. use more data
In terms of a WFO, use the Expanding Window.
2. make sure not to select peaks in an optimization space.
Ideally an optimum occurs at a peak that "rolls off" around it, which indicates to me that the results are not highly dependent on a specific set of parameter values. This is a stable optimization. You can evaluate and make this selection manually by observing the 3D optimization graphs.
Is there an indicator that can determine that? Very good question! If one doesn't exist already, it would be a good graduate project to develop a method that calculates a "score" by analyzing the results and their distance to an optimum.
----
Also, and not necessarily relevant to the question -
1. Make sure you don't use indicators that peek. The only reason some exist in WealthLab - and are so marked - are because customers wanted them.
2. If your strategy uses same-bar exits AND enters trades with stop or limit orders, make sure you're using WL8 Build 32 or later.
1. use more data
In terms of a WFO, use the Expanding Window.
2. make sure not to select peaks in an optimization space.
Ideally an optimum occurs at a peak that "rolls off" around it, which indicates to me that the results are not highly dependent on a specific set of parameter values. This is a stable optimization. You can evaluate and make this selection manually by observing the 3D optimization graphs.
Is there an indicator that can determine that? Very good question! If one doesn't exist already, it would be a good graduate project to develop a method that calculates a "score" by analyzing the results and their distance to an optimum.
----
Also, and not necessarily relevant to the question -
1. Make sure you don't use indicators that peek. The only reason some exist in WealthLab - and are so marked - are because customers wanted them.
2. If your strategy uses same-bar exits AND enters trades with stop or limit orders, make sure you're using WL8 Build 32 or later.
QUOTE:
2. make sure not to select peaks in an optimization space.
Ideally an optimum occurs at a peak that "rolls off" around it, which indicates to me that the results are not highly dependent on a specific set of parameter values. This is a stable optimization.
I totally agree. I often wondered how one could create an optimizer that would collect and rank all the maxima (outcome peaks) by their breadth. This is a tricky problem because you're doing this in multidimensional (R^n) space where n is the number of parameters you're trying to optimize. In addition, one has to come up with a breadth metric that's robust, so basing it on higher ordered statistical moments (e.g. kurtosis) is out of the question.
In a neural network (NN), one can limit the number of middle-layer nodes in a 3-layer NN to control over fitting. I suppose one could write a WL optimizer that's based on an NN design. It might execute kind of slow unless you're using a GPU accelerator card (e.g. CUDA Core hardware). Hmm.
Thinking and thinking about a way to see a clear quantitative or qualitative indicator of over-fitting:
Is it possible to see a graphic with "In Sample" metrics vs "Out of Sample"? It could be a Standard Deviation histogram of both populations, so discrepancies could be easily identified.
Any other idea? I'm still dealing with this big problem.
Is it possible to see a graphic with "In Sample" metrics vs "Out of Sample"? It could be a Standard Deviation histogram of both populations, so discrepancies could be easily identified.
Any other idea? I'm still dealing with this big problem.
QUOTE:
a way to see a clear quantitative ... indicator of over-fitting:
As a mentioned above, you need a robust metric that measures the multidimensional breadth of each maxima (optimized peak). You want to select solution peaks with a wide multidimensional breadth. This would be an area of numerical research (and would make an excellent dissertation topic) and is probably outside the scope of this forum.
Why don't you try posting your question to Cross Validated https://stats.stackexchange.com/ since they are more into numerical analysis and robust statistical methods there. Let us know what robust metrics they might recommend for measuring over fitting. As a numerical guy myself, I would be interested in any research done in this area.
IMPORTANT ASIDE: In a "traditional" linear system, there's a system matrix that one can determine a "condition number" from that depicts the stability (precision) of the system. But the optimizers we employ with WL do not solve traditional linear systems, so no condition number can be determined (at least not easily). With WL, we are dealing with discontinuous (i.e. event-driven) functions, so traditional numerical methods don't apply. :(
If there are some somewhat "established" robust metrics for estimating the breadth of each maxima, the optimizer authors might be able to incorporate these in their code and use these metrics to reject over-fitted peaks that lack enough breadth automatically. That would be a big plus.
---
Meanwhile, what you can do today is reduce the number of parameters in your strategy model to minimize over fitting. My two production strategies have 4 and 6 parameters in them. If I add any more than that, they would be over fitted.
Very clear Superticker. I will try this approach and reduce the number of parameters. I will look for redundances and I will try to find the key, uncorrelated ones.
What about this suggestion:
Whenever you run a backtest (in Strategy Window, Optimizer, Strategy Evolver, etc.) you do not calculate your performance metric for the Backtest interval but for two intervals instead:
An interval called "InSample or "IS" which is the first say 60% of your backtest interval.
A second interval called "OutOfSample or "OS" which is the remaining 40% of your backtest interval.
Then, whenever you judge a change to your system you check if the change improves both, IS and OS metric.
If your change improves the IS metric but lets the OS metric unchanged (or even worsens it) this is a clear sign, that this change adds to overfitting.
Whenever you run a backtest (in Strategy Window, Optimizer, Strategy Evolver, etc.) you do not calculate your performance metric for the Backtest interval but for two intervals instead:
An interval called "InSample or "IS" which is the first say 60% of your backtest interval.
A second interval called "OutOfSample or "OS" which is the remaining 40% of your backtest interval.
Then, whenever you judge a change to your system you check if the change improves both, IS and OS metric.
If your change improves the IS metric but lets the OS metric unchanged (or even worsens it) this is a clear sign, that this change adds to overfitting.
This process can be automated:
The finantic.Scorecards extension contains a Scorecard called "IS/OS ScoreCard".
This ScoreCard calculates IS and OS versions of all available performance metrics.
If you choose some of these IS/OS metrics in Preferences->Metric Columns then you'll see the combined results of IS metrics and OS metrics in each Optimization run or Strategy Evolver run.
The finantic.Scorecards extension contains a Scorecard called "IS/OS ScoreCard".
This ScoreCard calculates IS and OS versions of all available performance metrics.
If you choose some of these IS/OS metrics in Preferences->Metric Columns then you'll see the combined results of IS metrics and OS metrics in each Optimization run or Strategy Evolver run.
After an optimization it is very important to check for overoptimization.
To make such judgements simpler, the finantic.Optimizer extension contains a visualizer called "Parameters and Metrics".
This visualizer creates graphics which contain two performance metrics at the same time:
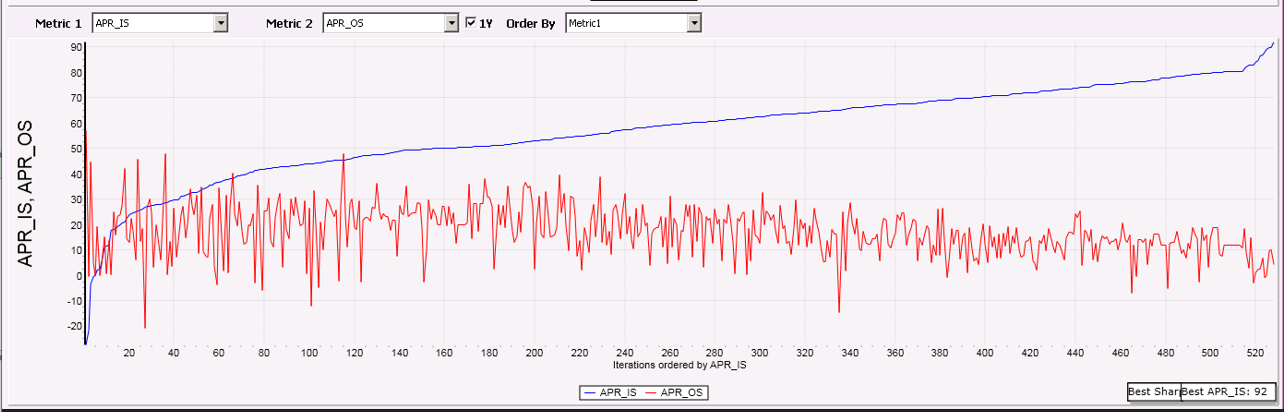
In the example above the blue line shows APR calculated in the IS interval. The optimizer was asked to optimize the performance metric "APR_IS" and as you can see it does a good job on improving this metric up to 90% (spectacular).
At the same time the red line shows the calculated APR for the OS interval.
It is obvious that the OS results lag far behind the IS results.
This is a clear sign of Overoptimization.
To make such judgements simpler, the finantic.Optimizer extension contains a visualizer called "Parameters and Metrics".
This visualizer creates graphics which contain two performance metrics at the same time:
In the example above the blue line shows APR calculated in the IS interval. The optimizer was asked to optimize the performance metric "APR_IS" and as you can see it does a good job on improving this metric up to 90% (spectacular).
At the same time the red line shows the calculated APR for the OS interval.
It is obvious that the OS results lag far behind the IS results.
This is a clear sign of Overoptimization.
I work on a similar solution (detection of overoptimization) for Strategy Evolver.
Hello DrKoch.
Just an additional comment. Identifying overfitting as you describe it is a well-known method. Afaik it is not relevant whether IS performs better than OS. The relevant part of this method is to identify a significant difference in results.That is the decisive criterion for overfitting.
Just an additional comment. Identifying overfitting as you describe it is a well-known method. Afaik it is not relevant whether IS performs better than OS. The relevant part of this method is to identify a significant difference in results.That is the decisive criterion for overfitting.
QUOTE:
it is not relevant whether IS performs better than OS. The relevant part of this method is to identify a significant difference in results.
IS results are calculated for a another historical period than OS results. This means there is (nearly) always a difference between IS and OS results.
As mentioned above the point is: Whenever you change the strategy, it is interesting to see if the change improves IS only or both, IS and OS.
A change can "only" improve the OS too while the performance keeps to be stable for the IS. This is not what you might looking for, but that clearly indicates an overfitting (EDIT: I should say data problem in the process of identifying over-fitted data) issue too. (Often information from backtests is discarded because a desired metric is not achieved. But even in this case, information is generated that is useful. Just pay attention to it...)
The difference (EDIT: more accurate is to talk of the error) of the results keeps to be the relevant information.
When the result for IS improves while the result OS does not, it indicates overfitting as you say. The other way around it is exactly the same.(EDIT: it is not the same issue but it is also a problem)
And of course there are deviations in the results, since they are also different data sets. The question is how far the results of the two data sets drift apart due to a change in strategy. The more the results diverge, the more likely overfitting is part of the problem.
The difference (EDIT: more accurate is to talk of the error) of the results keeps to be the relevant information.
When the result for IS improves while the result OS does not, it indicates overfitting as you say. The other way around it is exactly the same.(EDIT: it is not the same issue but it is also a problem)
And of course there are deviations in the results, since they are also different data sets. The question is how far the results of the two data sets drift apart due to a change in strategy. The more the results diverge, the more likely overfitting is part of the problem.
Well, as a rule, the "in-sample error" is smaller than the "out-of-sample error". The reason for this is that the noise in the "in-sample" is taken into account. As soon as the out-of-sample data is used, there is a new unknown noise.
If the error in the "in-sample" becomes smaller and smaller but not in the "out-of-sample", we speak of overfitting. If the error in the out-of-sample data is smaller than the error in the IS, one has to ask why. There can be several reasons that have to do with the data.
So if you want to know if training, testing and validation data is "healthy", then that should be taken into account.
If the error in the "in-sample" becomes smaller and smaller but not in the "out-of-sample", we speak of overfitting. If the error in the out-of-sample data is smaller than the error in the IS, one has to ask why. There can be several reasons that have to do with the data.
So if you want to know if training, testing and validation data is "healthy", then that should be taken into account.
Your Response
Post
Edit Post
Login is required